

How To Implement Fully Automated Service Discovery & Registry In Cluster Management
Introduction:
In this blog,you are going to learn the very important building block for any distributed system i.e. the java development Service registry. I will explain here how java development service discovery in the cluster works and will implement it using Apache zookeeper.
Cluster Management, Service Registration and Discovery
What is service discovery?
When a gathering of PCs fires up, the main gadget they know about is themselves regardless of whether they're completely associated with a similar network. The formal legitimate cluster the various hubs need to get some answers concerning each other in some way or another. They have to realize who else is in the bunch and above all how to speak with those different nodes.
The clear straightforward arrangement can be a static setup. We just discover all the hub's addresses early and afterward, we put them all on a solitary design document and disperse the record among all the nodes before we dispatch the application. Thus, all the nodes can speak with one another utilizing those addresses.
The issue obviously is on the off chance that one of the hubs gets inaccessible or changes its location after it gets restarted for reasons unknown different hubs would even now attempt to utilize the old location and will always be unable to find the new location of the node. Likewise, on the off chance that we need to grow our group, we'll need to recover this document and appropriate the new record to all the nodes.
Actually, nowadays, a ton of organizations deal with their clusters likewise with some level of robotization/automation. For instance: each time we add another node, we can refresh one focal spot with the new setup. At that point, an automated configuration management tool such as chef or puppet and afterward push the design to the whole group and update each node arrangement naturally. This way the design is more powerful however may, in any case, include a human to refresh the configuration.
Fully automated service discovery using zookeeper
The approach we are going to take is using a fully automated java service discovery using a zookeeper. The idea is as follows:
We're going to start with a permanent Z node called service_registry. Every node that joins the cluster will add an ephemeral sequential node under the service registry node in a similar fashion as in the leader election.
Unlike in the leader election, in this case the Z nodes are not going to be empty. Instead each node would put its own address inside its Z node.Now that was the service registry part.
The service discovery now is very easy to implement. Each node that wants to communicate or even just be aware of any other node in the cluster is to simply register a watcher on the service registry Z node using the getChildren() method. Then when it wants to read or use a particular nodes address, the node will simply need to call the getData() method to read the address data stored inside the Z node and if there is any change in the cluster at any point, the node is going to get notified immediately with the no children changed event.
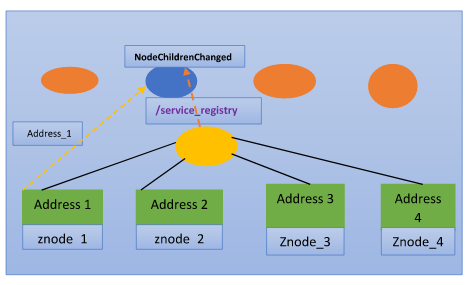
Potentially with this execution, we can actualize a completely shared design(peer-to-peer architecture) where every node can discuss uninhibitedly with any node in the group. In that design if a node is done or another node joins the bunch, all the hubs will get changed and will act as needs be.
In the Leader/Workers engineering/architecture, the workers don't have to think about one another at all and nor does the pioneer require to enroll itself in the library. Thus, the workers will enroll themselves with the group however just the pioneer will really enlist for notices. Thusly and the Leader will know the condition of the whole group consistently and will have the option to appropriate the work in like manner. Additionally, if the leader bites the dust the new leader will eliminate it self from the administration vault and keep dispersing the work.
The service registry:
In this blog, you are going to learn about a very important nothing but the building block in distributed systems the service registry. You’ll also learn about a few different approaches to the problem and learn how to implement the service registry and service discovery using Apache zookeeper.
Apache zookeeper is used by many companies and projects for service discovery in production. However, there are many other tools and technologies that offer comparable capabilities :
etcd
Consul
Netflix Eureka
There are numerous different tools additionally there. Having a mechanized help revelation permits our framework to be entirely adaptable and dynamic as nodes can be added or eliminated anytime. One more thing I need to call attention to is we actually need to disseminate the adders of zookeeper to the whole cluster. Along these lines, the static or to some degree manual configuration management approach I referenced in the start of the blog is still truly important in spite of its impediments. Presently I will execute the service discovery progressively in real-time.
Implementation of Service Registry& Service Discovery:
Now we will execute the service registry in real-time. Also, later we will incorporate it with our Leader, workers cluster engineering/architecture. Along these lines, we should feel free to actualize the service registry utilizing zookeeper.
As a fast update on connection to zookeeper, each and every node is going to create an ephemeral znode under the service registry parent and store its address in its znode for others to see.
Then any node that is interested in getting the address of another node simply needs to call getChildren() to get all the existing znodes under the service registry and then call the getData() method to read the address inside the znode. We can really store any configuration inside the znode but we must not forget that the znodes are not files on the file system but are stored in memory inside the zookeeper servers. So, we need to store the minimum data to allow communication within the cluster.
Storing Configuration/Address:
In our case we're going to store the host port combination as the address which will be enough to establish that communication. Here, in my explanation, I am going to separate the leader election logic from the rest of the application into separate classes. Now the leader election class takes the zookeeper object into its constructor and contains the familiar to us volunteerForLeadership()method and their reelectLeader() method.
The class also implements watcher like before but now it handles only the Node Deleted event which is the only relevant event for the leader election. The Application class has the familiar connectToZookeper(),run() and close() methods and it also implements Watcher.

But in the Application's process() method, it only deals with the connection and disconnection events from zookeeper. In the main() method we first create our application instance and obtain the zookeeper object by connecting to zookeeper. Then we perform all the leader election logic and in the last part we call the run() method which suspends the main thread.


There's nothing really new so far but this organization will allow us to grow our application while maintaining the separation of concerns among the different classes.
Implementing Service Registry:
So now create a cluster management package. In that package will create a new class called ServiceRegistry. This class will encapsulate all the service registry and discovery logic. At the top let's declare the registry znode name which is the parent znode for our service registry. The service registry class will also hold a reference to zookeeper, which we will pass into it through the constructor.
Now the first thing we need to do is to create the service registry znode or at least make sure that the already exists. So, let's define the createServiceRegistryZnode() method inside the method we check if the znode already exists by calling the exists() method and checking its return value. If the return value is null, then at the time of checking that znode did not exist. So, let's call the create() method but this time using the persistent create mode. This way znode will stay there forever. So, we don't have to recreate it every single time.


Notice that there is a small race condition here between the exists() method and the create() method. If two nodes call exists in the same time, then they would both get null and proceed to create the same service registry znode. This race condition is solved by zookeeper for us by allowing only one call to the create() method on the same znode path to succeed.
The second call would simply throw a KeeperException which we kind of swallow in this method by catching it and not doing anything special. Now let's call that method in the constructor so that every node that creates the service registry object will check that the service register znode exists and if it doesn't it would be created for us.
Now let's implement the logic for joining the cluster. So, let’s create the registerToCluster(String metaData) ()method which takes a metadata string as an argument. This metadata can be any configuration we want to share with the cluster. In our case it's going to simply be the address of the node. First let's create a member variable to store the znode we are going to create.
Then we call the zookeeper create() method which takes the path to our znode under the registry znode parent. Then we have to pass the metadata's binary representation which we will store inside the znode and the znode is going to be ephemeral sequential to tie this znode’s lifecycle to the lifecycle of this particular instance of the application.
By making it sequential. We simply avoid any name collisions, but the actual sequence number is not important for us at this time. In the end we simply print out that we registered to the cluster and that's all we need to do to register our address with the service registry.

Service Discovery Implementation
Now let's implement the logic of getting updates from the service registry about nodes joining and leaving the cluster. So, let's create the synchronized updateAddresses() method which will be called potentially by multiple threads.
Also, we have to create the list of service addresses that will store a cache of all the nodes in the cluster to avoid calling getChildren() every time we need the list of all the addresses. Inside the updateAddresses(), I am calling first the zookeeper getChildren() method on the registry znode parent both to get the current list of children but also to register for any changes in that list. To get those notifications we first need to implement the Watcher interface and define the process method which will handle those events.
Then I have created a temporary list to store all the cluster's addresses. After that we iterate over all the children znodes, construct the full path for each znode. Then called the exists() method on that child znode to get its stats as a prerequisite for getting the znode's data. If between getting the list of children and calling the exists() method that child znode disappears. Then the result from the method is going to be null.
This is yet another race condition that we have no control over, but we handle it by simply continuing to the next znode in the list. There is somewhat a mind shift we need to make between race conditions in multithreading, which we can easily solve with a lock whereas in distributed systems some race conditions we simply need to learn how to anticipate and recover from.
If the znode does exist, then we called a getData() method on the znode's path. Then we convert those bytes into an address string and add that address into the list of addresses. When we're done getting old addresses from the service registry, we will wrap that list with an unmodifiable list object and store it in the all service addresses member variable.
Because the method is synchronized, this entire update will happen atomically. In the end we simply print out the addresses we have in our cluster. At this point we don't only have all the addresses stored in a member variable, but we are also registered for updates about any changes in the cluster.
updateAddresses() method:
Now, I am going to write code to handle those changes events inside the process() method. We're simply calling the updateAddresses() method. Again, this will update our all service addresses variable and reregister us for future updates. The one thing we're missing right now is the initial call to updateAddresses(). So, let's create the registerForUpdates()method which will simply call to updateAddresses() method after a leader has registered for those updates.
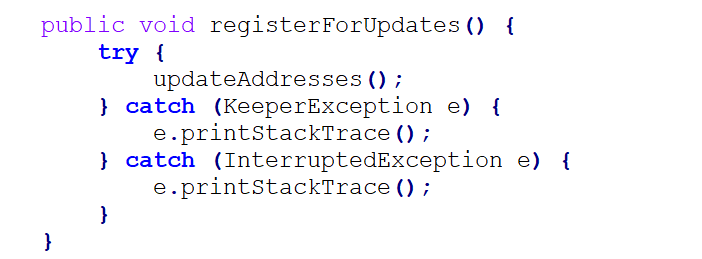
It may also want to get the list of the most up to date addresses. So, let's create the synchronized List<String> getAllServiceAddresses()method which will give us those cached results. If the allServiceAddresses is null, then the caller simply forgot to register for updates. So, to make this call safe we will first call to updateAddresses() method and in other case we will return the all ServiceAddresses to the caller.

The last feature we need to add is the ability to unregister from the cluster. This is very useful if the node is gracefully shut down itself or if the worker suddenly becomes a leader. So, it would want to unregister to avoid communicating with itself.
Now let's create the unregisterFromCluster() method which will first check that we indeed have an existent znode registered with the service registry and then we simply delete it by calling the delete() method and that's it. The service registry implementation is ready now and that means our service registry is ready.

Integrating into Leader-worker Architecture:
Let's integrate with our leader, workers architecture since our programming model is event driven. We need a way to trigger different events based on whether the current node was elected to be a leader, or it became a worker in order to keep the service registry and discovery separate from the leader election logic. We will integrate the two using a callback.
So, now let's create an interface called OnElectionCallback.
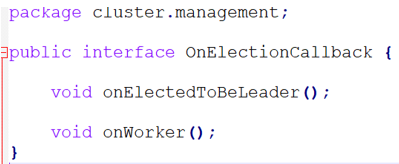
The interface will require the implementing class to implement two methods. TheonElectedToBeLeader() and the onWorker() methods. After every leader election, only one of those methods will be called with this callback-based approach. The modifications to the leader election class are going to be minimal. We simply store the reference to the own election callback which is passed into the leader election class through its constructor.
Then in the reelectLeader()method, if we are elected to be a leader then before returning from the method, we call the on elected to be leader callback method. And if we're not a leader but a worker then we call onWorker() callback method instead. And these are the only changes we need to make in the leader election.
Now all we need to do is create a class that would implement those callbacks. So, let's create the onElectionAction class which implements the onElectionCallback. We just created the class will hold a reference to our service registry and the port which will be part of our application's address those parameters are going to be passed into the class through its constructor’s arguments.
If the onWorker() callback method is called, then we create the current server address by combining the local hostname and the port as a single string and then we call the registerToCluster() method of the address as the metadata we store for others to see.
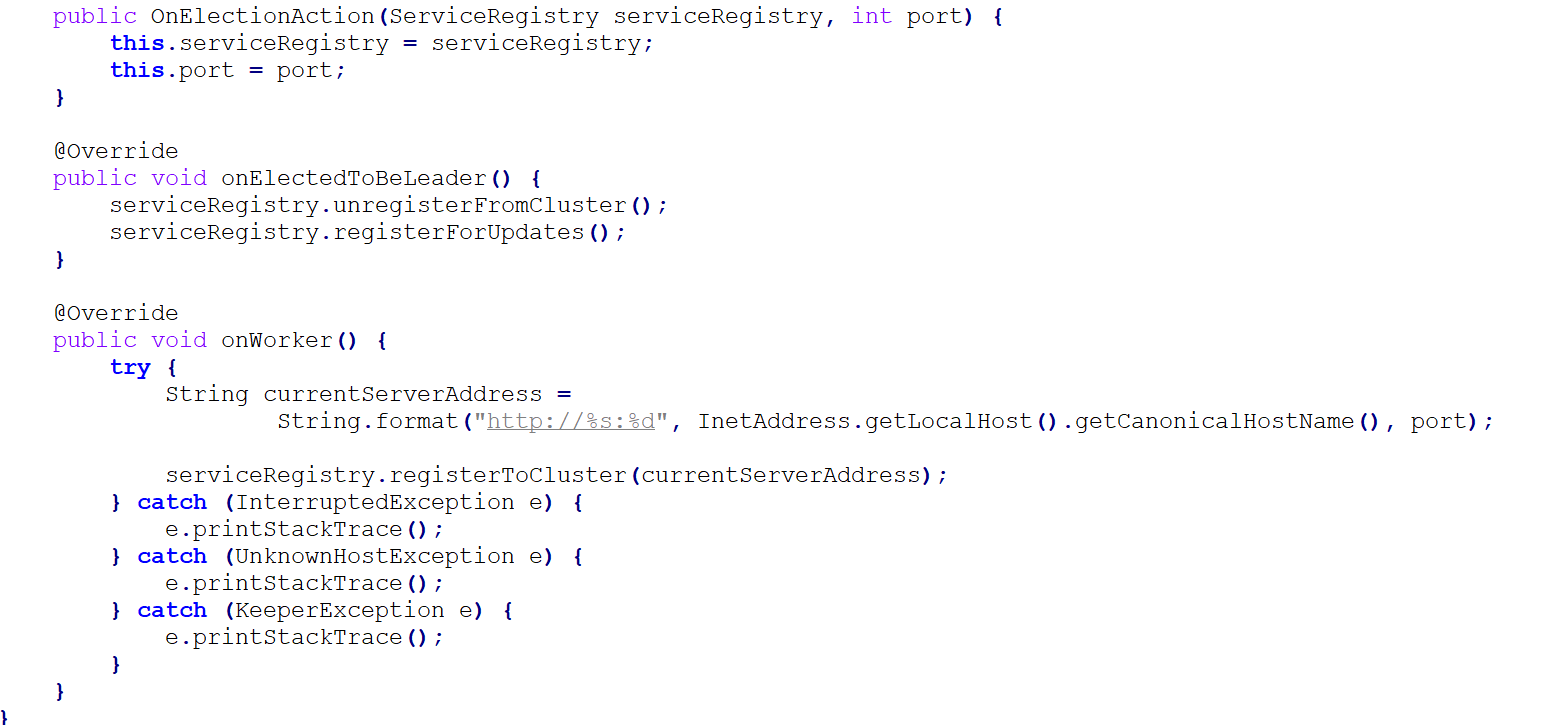
On the other hand, as you can see in the above code snippet, if the current node was elected to be a leader,then we first call unregisterFromCluster()method. If the node just joined the cluster this method won't do anything but if it used to be a worker. But now it got promoted to be a leader. Then it would remove itself from the registry. After that we simply call registerForUpdates() and that's it.
The last thing we need to do to glue everything together is go back to the Application class. Need to define a default port for our application and then parse the port from the application's arguments. If the port was not passed into the application as an argument, then we will simply use the default port. The reason for that logic is if we run the application instances on different computers then we can simply use the default port as the address of each node will be different. In this case because we are running the nodes on the same machine, we'll need to pass a different port for each instance.

After we have the port, we simply need to create the service registry. Then the onElectionAction object which takes the service registry and our application's port and finally the on ElectionAction instance is passed into the leader election class as the implementation for that onElection callback and that's it.

Our integration of the service registry to our master workers architecture is now complete. Now let's build and package the application and open 4 terminal windows. Let's launch the first node with the port 8080 since this is the first node to join the cluster. It became the leader and it registered for updates from the service registry which is still empty.

Now on the right let's launch another node with the port 8081. And of course, it joined as a worker. So, it registers itself with the service registry as soon as it did that the leader got the notification that the list of nodes in the cluster changed. And now it shows the newly added worker address in its list.
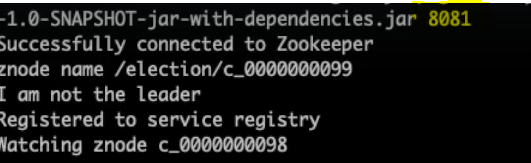
Now similarly we can launch another worker with the port 8082 which triggers another update on the leader side. And finally let's add the fourth node which is also a worker and now the leader has all the addresses of all the nodes in the cluster at this point it can freely send messages or tasks to all the workers until that list changes.

So, let's test the scenario of a node leaving the cluster unexpectedly by killing the right bottom node. Within the session timeout, the leader will get notified that the list of nodes changed and now it will have only two nodes in his group of workers. If that node is restarted (with java -jar command) and it rejoins the cluster, the leader will get notified about it again.
So, you can verify that with this configuration. Our cluster can grow and shrink dynamically, and we don't need any human intervention to update any configurations. It all just happens automatically.
Finally you can test a scenario of the leader itself leaving the cluster and the new leader will take all the old leader's responsibilities and it unregisters itself from the workers pool and now it will have the addresses of all the remaining worker nodes so it can resume any work that the old leader was planning to distribute to all its workers.
And obviously if the old leader decides to rejoin the cluster again it will join as a worker. So, its address will be registered in the service registry and the current leader will get it instantaneously.
Conclusion
In this blog, I mentioned about the implementation by java developmet services company of a fully automated service registry and discovery within the cluster using zookeeper using the service registry nodes can both register to the cluster by publishing their addresses and the register for updates to get any other nodes address. Also, I described about the integration of the service registry with the leader election algorithm using callbacks and then tested our implementation under multiple scenarios which proved our service registry is fully functional.
FAQs:
Subject: Cluster Management, Service Discovery and Service Registry
What is Service discovery in cluster Management?
How to implement fully automated service discovery using zookeeper?
How to integrate with leader/worker architecture?
Example of Service Registry implementation in Zookeeper in Java?
How can you achieve cluster management using zookeeper?



